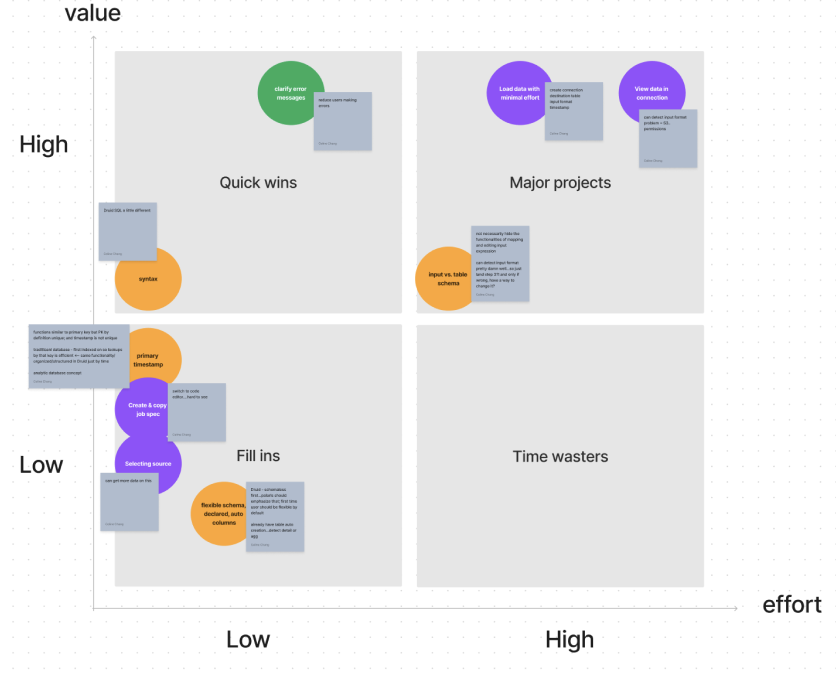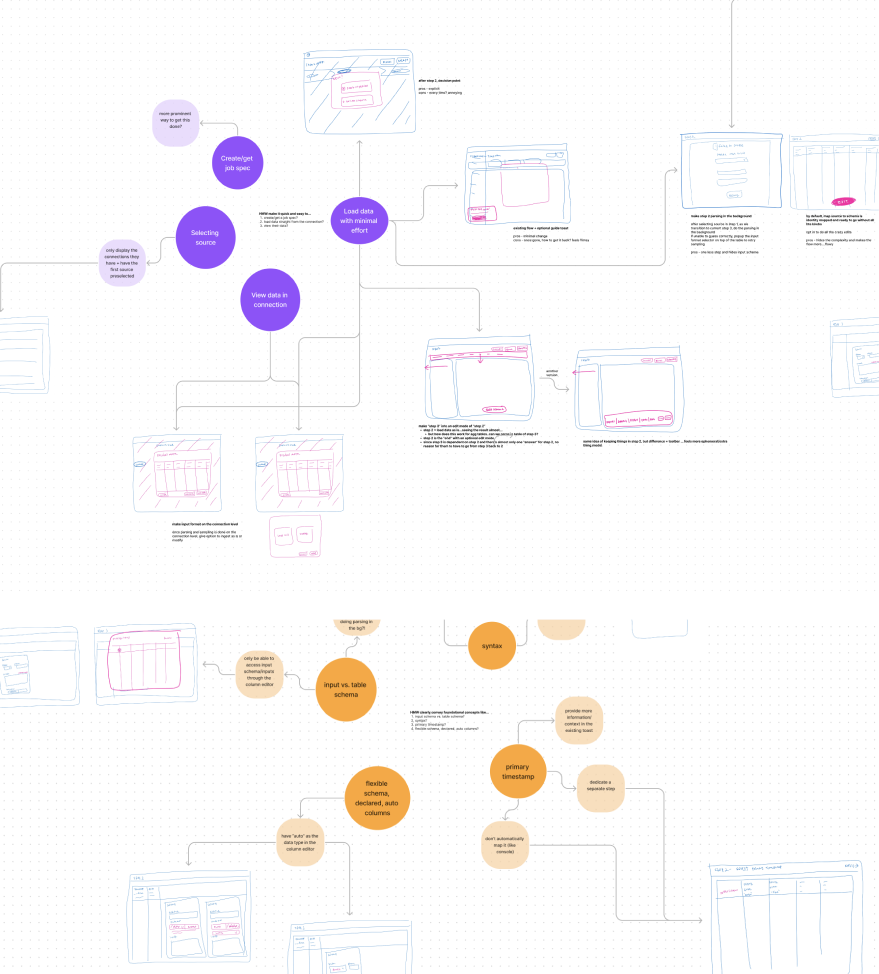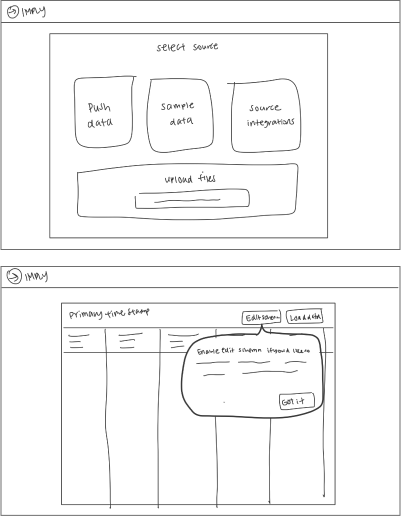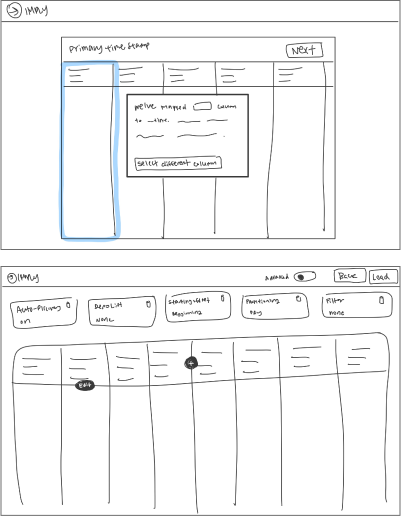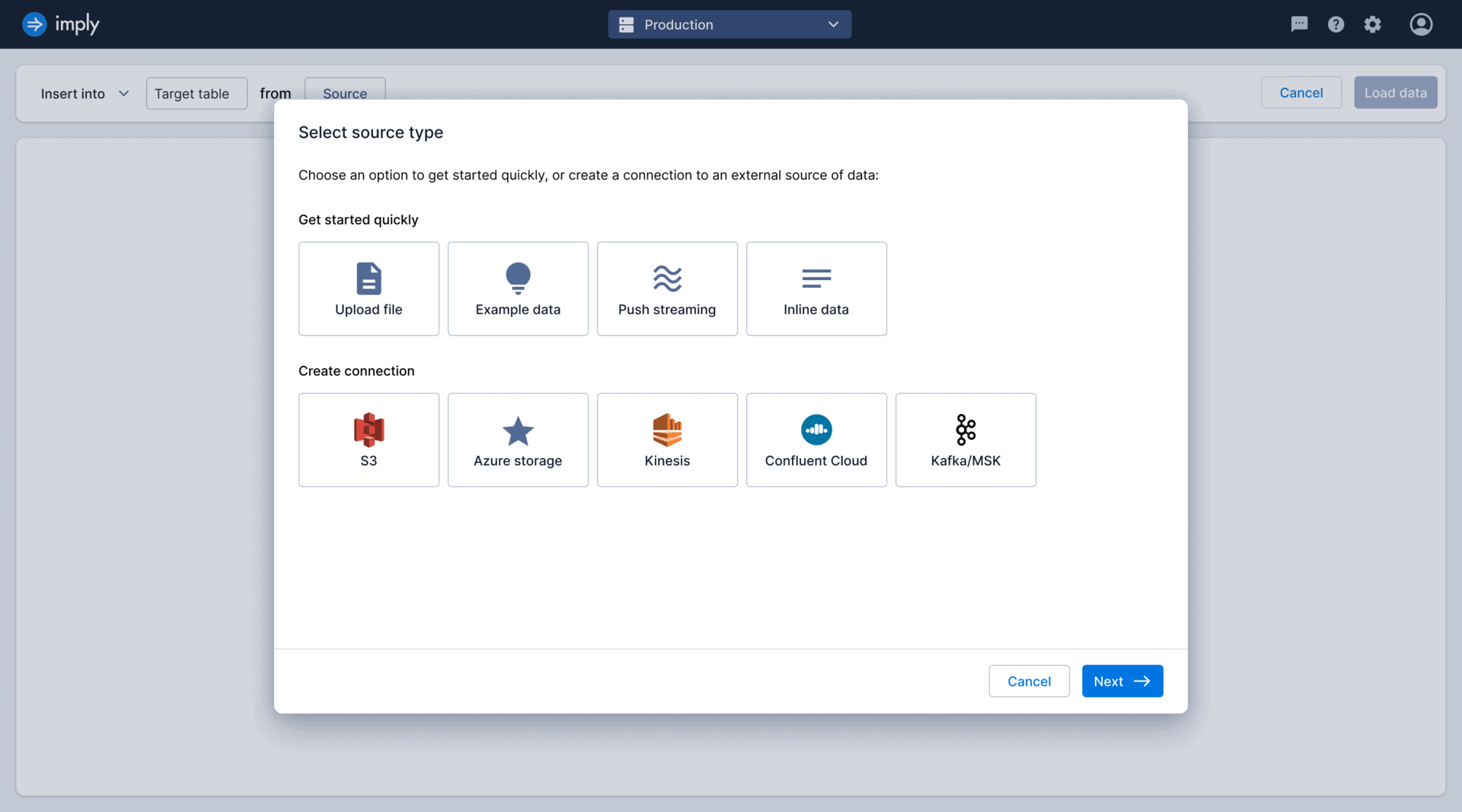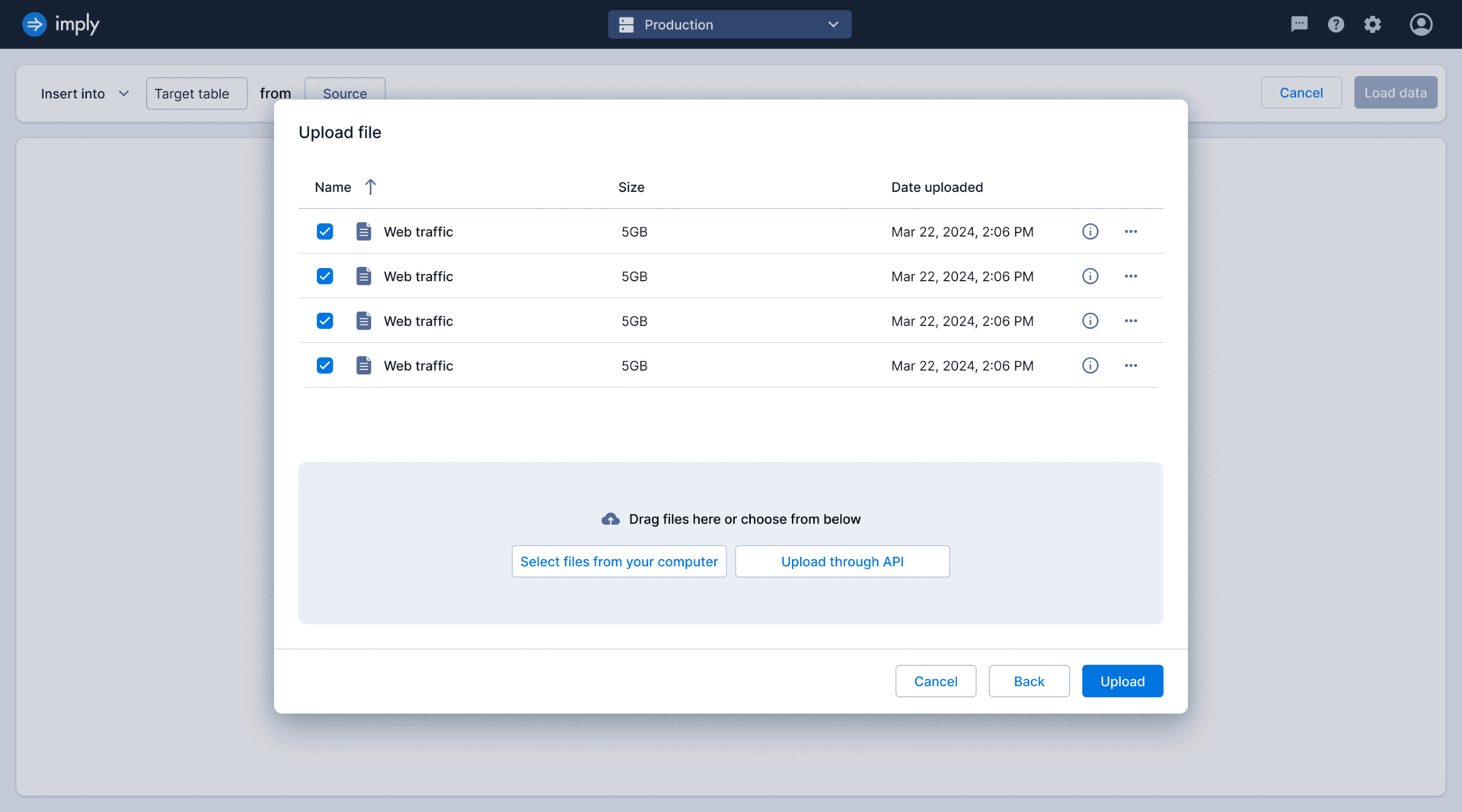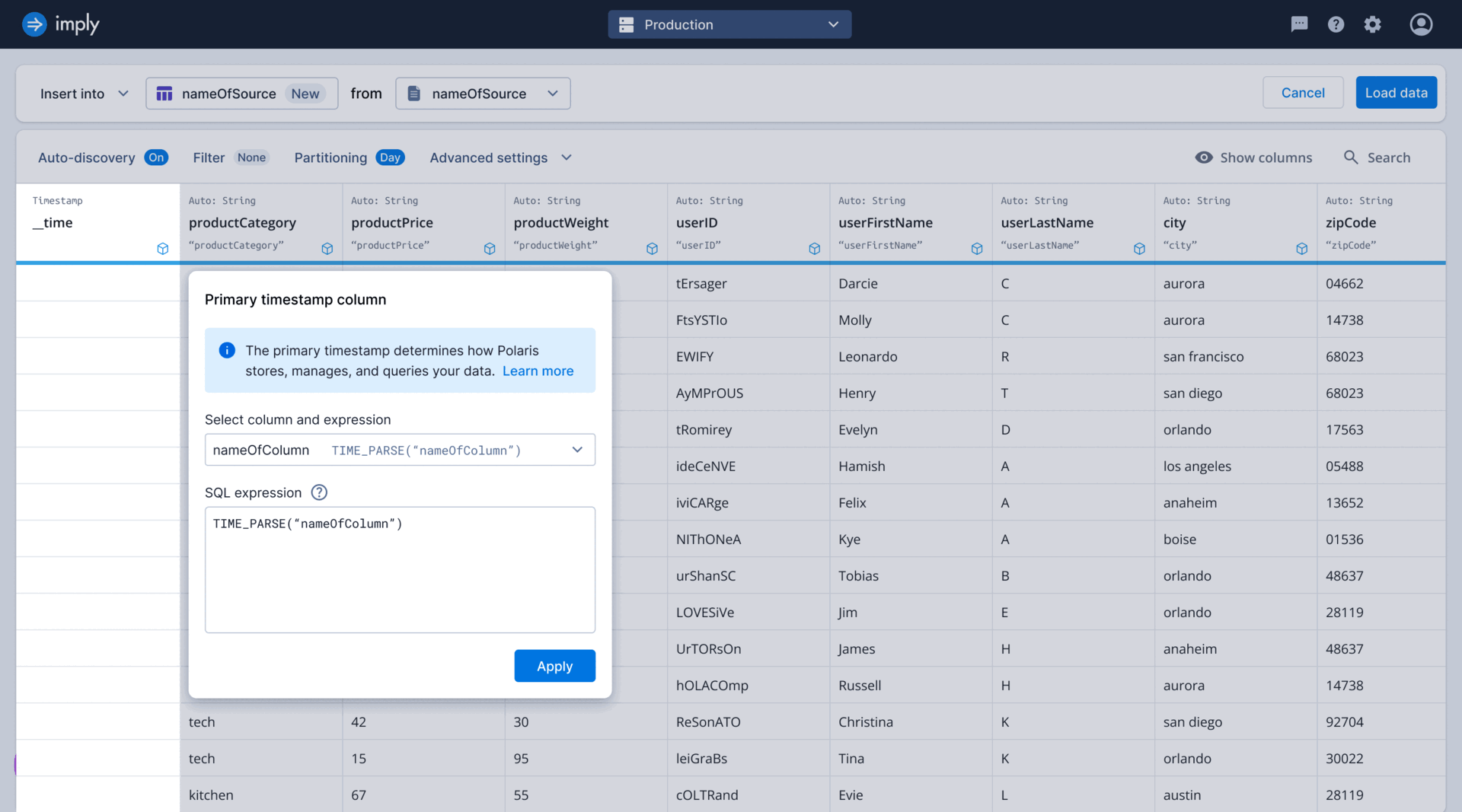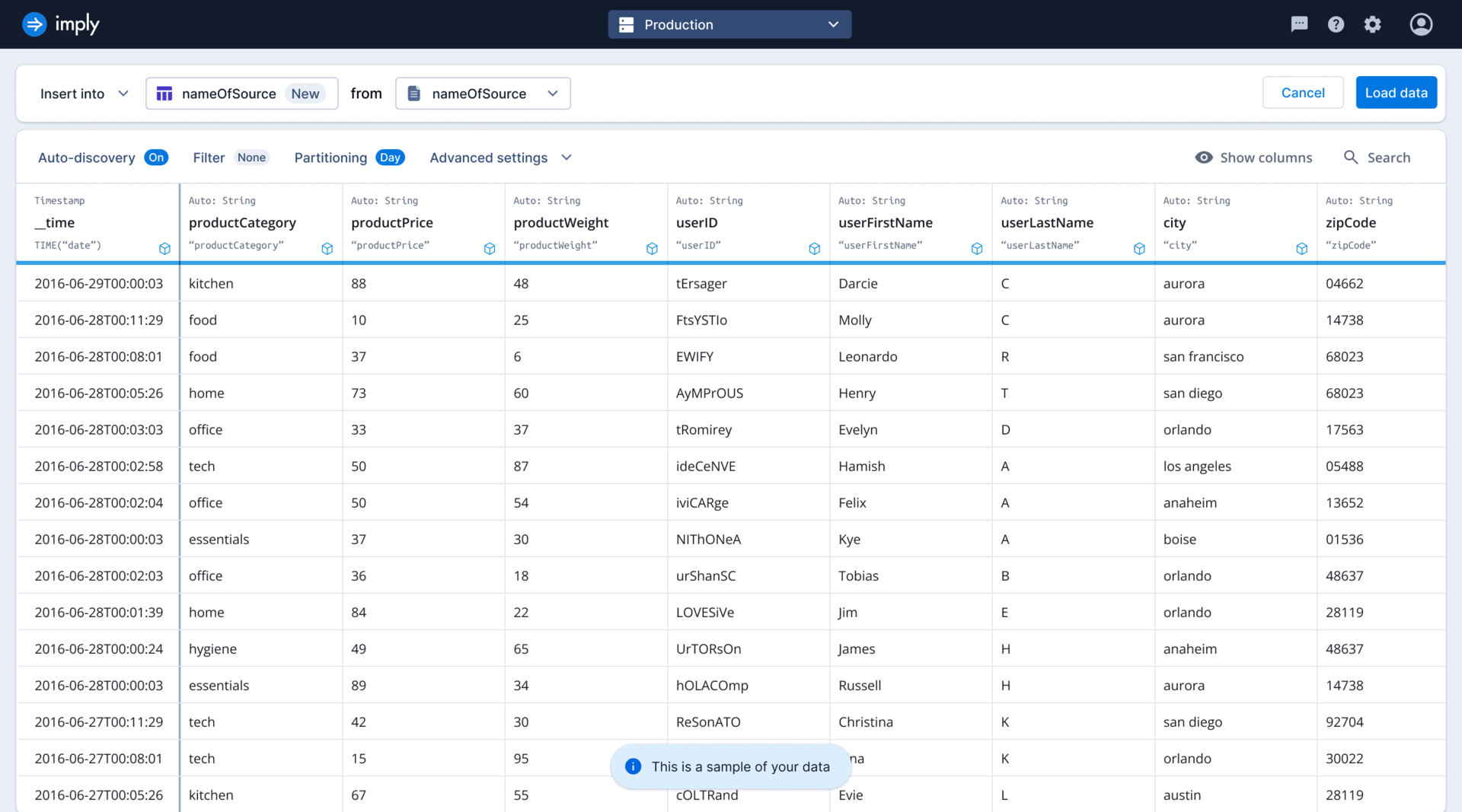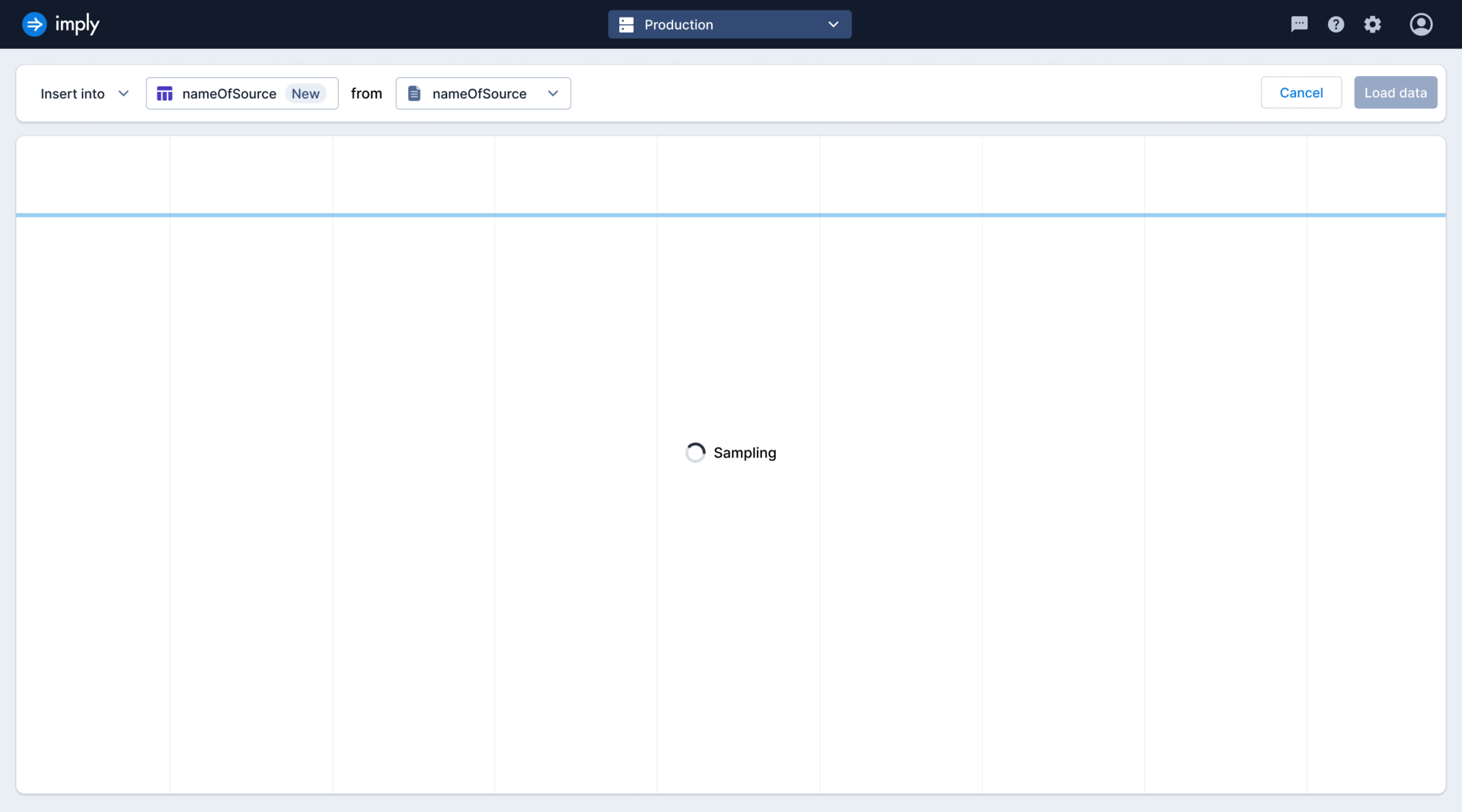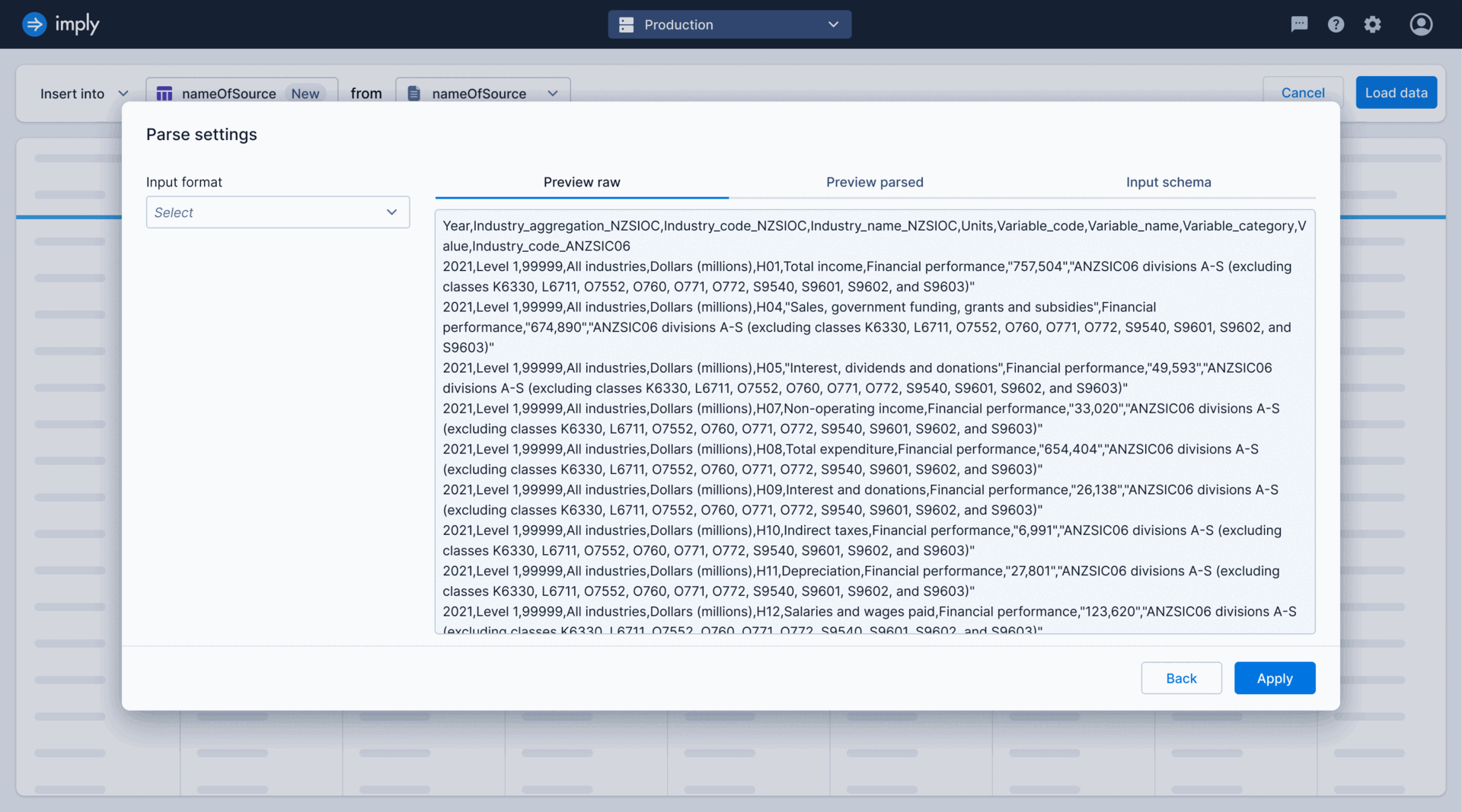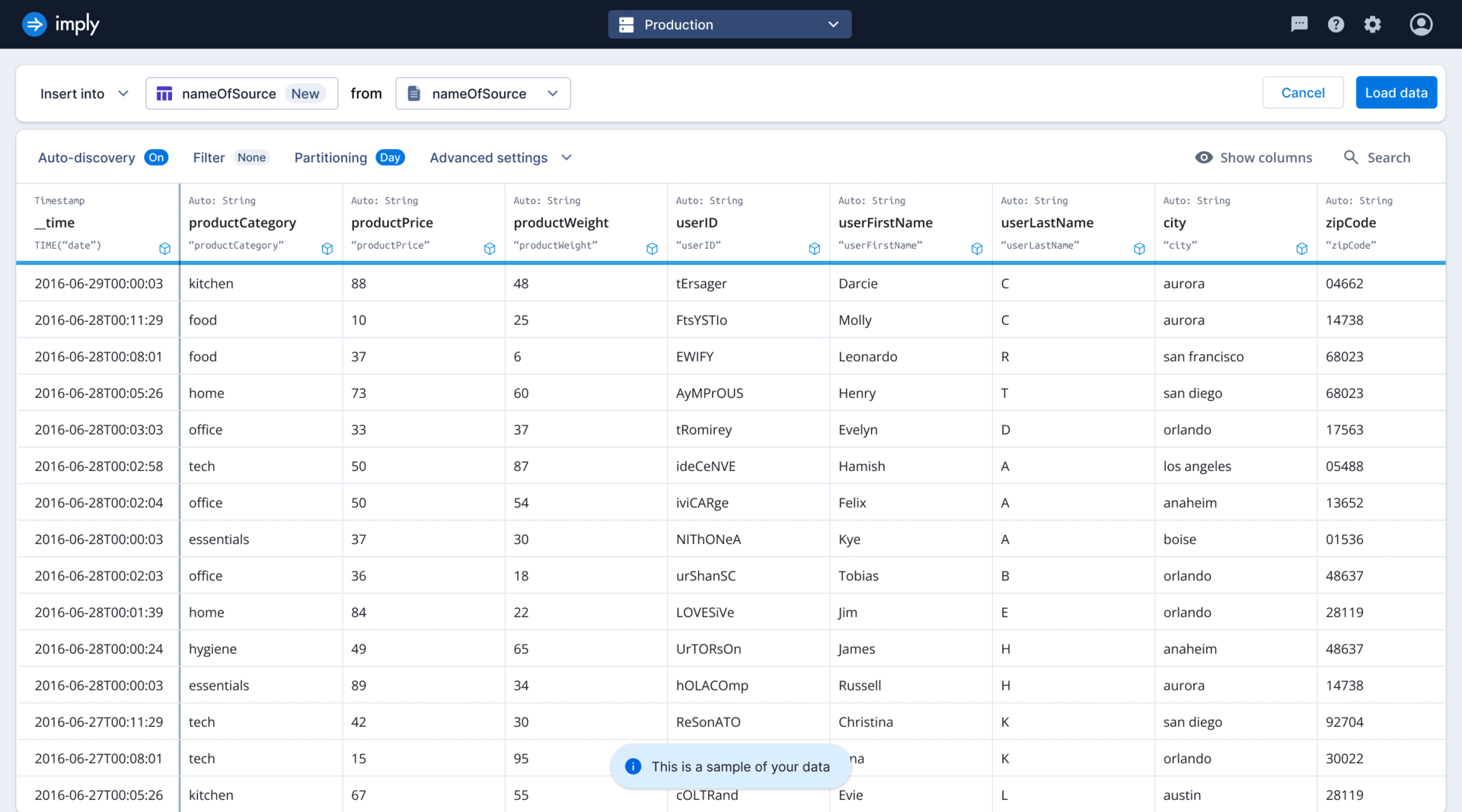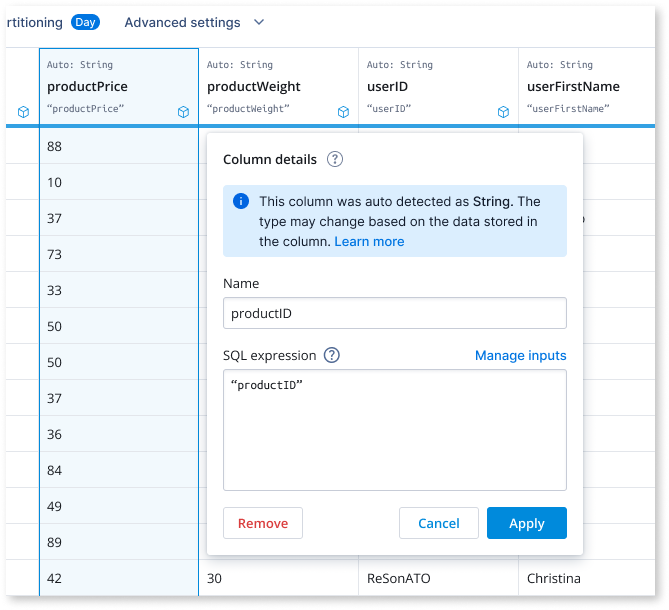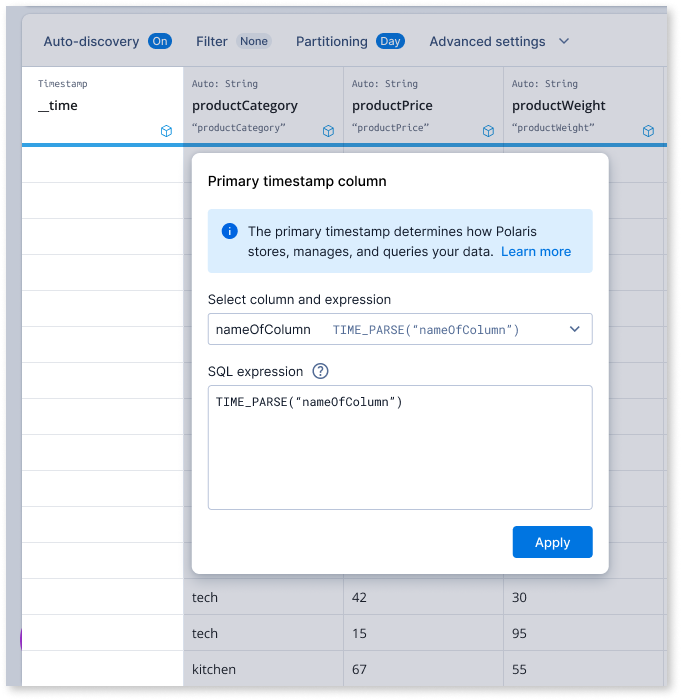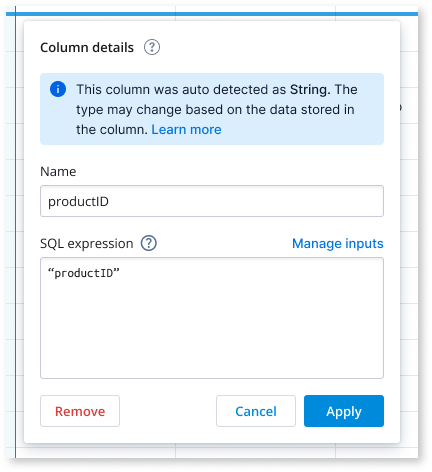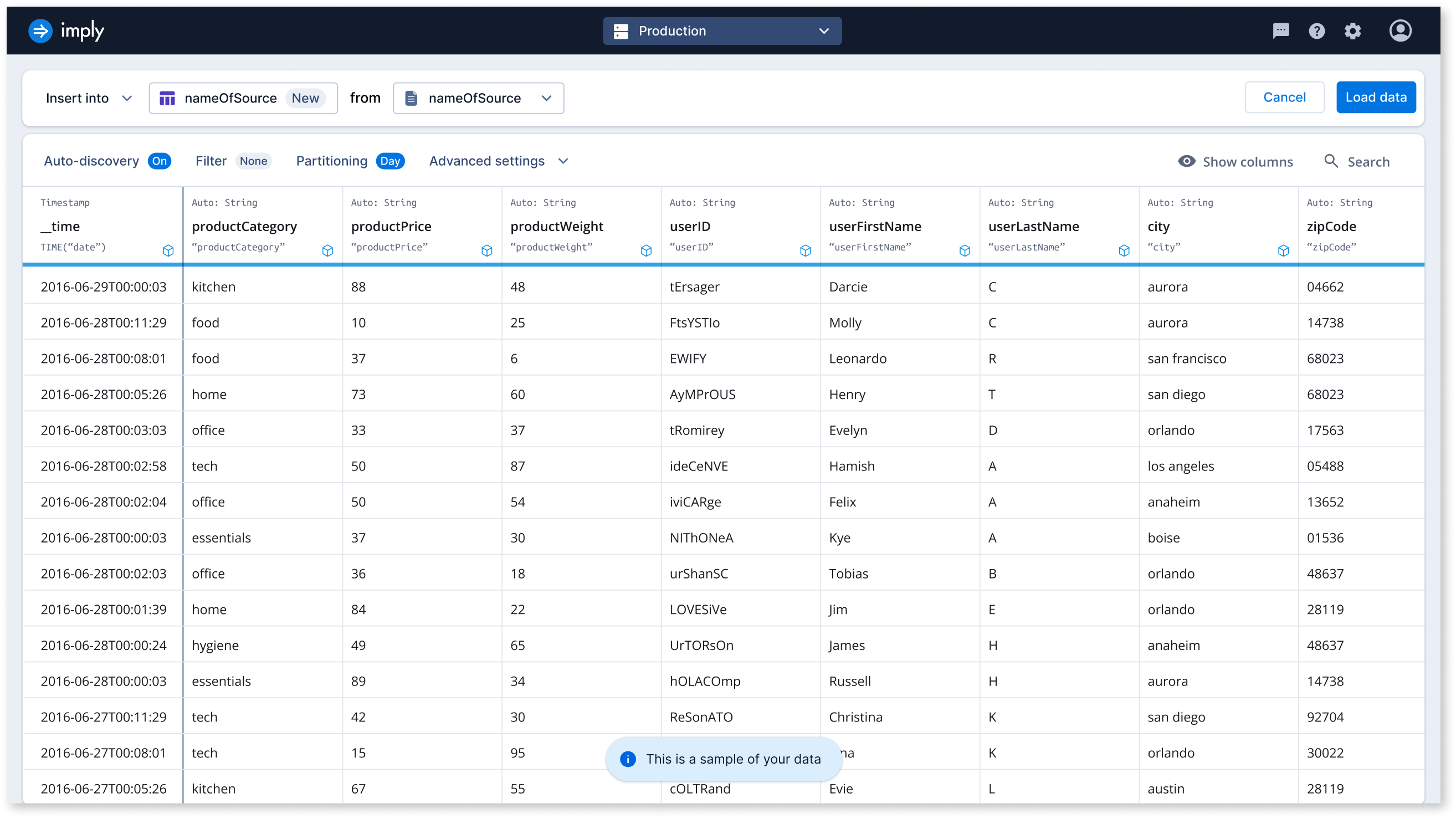
As the sole designer on the project, tackled high drop-off rates in the ingestion funnel by co-leading research initiatives to identify key issues. Collaborated closely with the PM and EM to brainstorm and develop solutions throughout the entire design process.
user research
Conducted 1) Semi structured interviews with existing customers to understand their usage patterns, initial experiences, and overall perception of the product and 2) usability testing with non-users to understand the usability of the product – validating what works while uncovering issues
Goals


Insights